
Cómo automatizar procesos de negocio sin complicarte la vida
La automatización de tareas nunca ha estado tan al alcance de todos como ahora, gracias a la amplia oferta de herramientas low-code y no-code disponibles en el mercado. Plataformas con una larga trayectoria, como IFTTT, Zapier y Make (anteriormente conocida como Integromat), y otras más recientes, como Pabbly Connect, ofrecen una amplia variedad de alternativas para conectar aplicaciones de forma intuitiva.
Índice de contenido
Otras opciones van desde soluciones accesibles y básicas, como Automate.io, hasta herramientas más avanzadas y especializadas, como n8n, Tray.io o Power Automate de Microsoft. Con tantas posibilidades a mano, es fácil caer en la tentación de registrarse y empezar a experimentar para descubrir hasta dónde se puede llegar.
Estas herramientas suelen estar bien documentadas, cuentan con comunidades de usuarios muy activas y una gran cantidad de tutoriales tanto oficiales como de aficionados. Sin embargo, seamos honestos, la curiosidad suele ganar la partida y muchos prefieren lanzarse a explorar por su cuenta después de ver un par de vídeos en YouTube. Eso sí, rara vez se puede replicar el procedimiento al pie de la letra, y la necesidad de ir adaptando el flujo a nuestro caso (quedando a veces atrapados en bucles de ensayo y error) conlleva avanzar muy lentamente.
Este enfoque de ir «sobre la marcha» puede funcionar para aplicaciones sencillas, pero para evitar invertir demasiado tiempo en desarrollos más complejos sin obtener los resultados esperados, hemos recopilado tres recomendaciones clave para quienes se inician o tienen una experiencia limitada en la creación de automatizaciones:
- Empieza por el final
- Cuidado con la elección del trigger
- Aprende a leer el log para hacer troubleshooting



1. Empieza por el final
Aunque pueda parecer contraintuitivo, «empezar por el final» es una estrategia ampliamente utilizada en el ámbito informático, y las herramientas de automatización de procesos no son la excepción.
Estas plataformas destacan por su facilidad de uso e intuitividad, con interfaces de arrastrar y soltar que facilitan la creación de flujos. Por lo tanto es muy tentador empezar a añadir elementos al proceso sin prestar atención al objetivo final. Sin embargo, método presenta el riesgo de encontrarse en un callejón sin salida, puesto que cada paso del flujo suele depender del anterior. Esto reduce la flexibilidad para realizar cambios una vez que has avanzado en el desarrollo y puede hacer que cualquier modificación a mitad de camino implique la necesidad de rehacer buena parte del flujo.
Por eso, a la hora de desarrollar flujos de automatización, es fundamental definir la estructura base desde el principio y modificarla lo menos posible. La mejor forma de lograrlo es empezar por el final: identifica el último paso y determina qué datos y parámetros requiere la aplicación de destino para ejecutar la acción deseada. Esto te permitirá razonar «hacia atrás», asegurando que cada paso anterior genere la información necesaria para el siguiente.
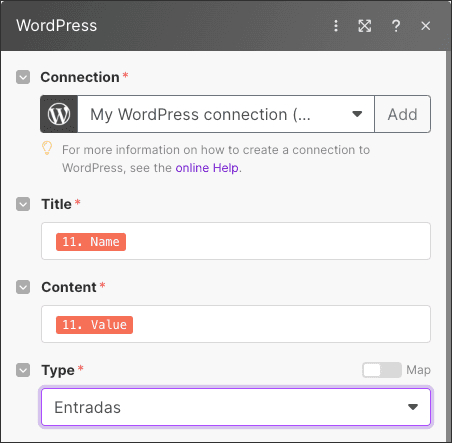
Pongamos un ejemplo práctico: imagina que quieres usar Make para crear, a partir del input de un usuario, una nueva entrada de blog en WordPress generada por inteligencia artificial. Para que WordPress admita las nuevas entradas a través de su integración con Make, hay ciertos datos que son imprescindibles, como el título, el contenido y el tipo de publicación (entrada, página, etc.).
Ahora bien, probablemente no quieras limitarte a lo básico, sino que también necesites personalizar la configuración de la entrada, por ejemplo, marcarla como borrador para revisarla, antes de publicarla, mantener la organización, aplicando categorías y etiquetas o asignar un autor.
Además, es fundamental tener en cuenta el tipo de datos que admite cada campo. Si, por ejemplo, quieres establecer una fecha de publicación, deberás asegurarte de introducir la fecha en uno de los formatos que WordPress reconoce. De lo contrario, el flujo podría fallar o generar errores inesperados.
Aquí es donde se aprecia la importancia de «empezar por el final», porque todos los datos obligatorios y los opcionales que vamos a incluir se tendrán que recopilar en los pasos anteriores del procedimiento, en el formato adecuado.
2. ¡Cuidado con la elección del trigger!
El segundo paso clave es elegir el trigger, es decir, el evento inicial que activa el flujo automático. Esta decisión no siempre es sencilla, ya que los triggers pueden variar mucho en función del sistema y el objetivo que se quiera alcanzar. Además, cada tipo de trigger tiene sus propias limitaciones, lo que influye en la forma de configurar los pasos siguientes y en la facilidad de desarrollo del flujo.
En plataformas como Make, hay decenas de triggers disponibles para cada integración, por lo que elegir el más adecuado suele requerir tiempo y pruebas. Los triggers más habituales incluyen:
- Recepción de un email en una cuenta específica, o cualquier otro tipo de notificación.
- Subida de un archivo a una carpeta en la nube.
- Envío de un formulario o la modificación de un campo en una base de datos, como una simple celda de Google Sheets.
También existe la posibilidad de programar activaciones automáticas sin necesidad de un evento externo. Por ejemplo, se puede configurar un flujo para que detecte cambios en una carpeta a intervalos fijos (por ejemplo, cada 15 minutos o una vez a la semana… y todo lo que hay entre medio). En este caso, es importante ajustar bien la frecuencia para prevenir dos situaciones comunes:
- Intervalos demasiado frecuentes: se consume el límite de operaciones de la suscripción.
- Intervalos demasiado amplios: se acumulan demasiados cambios y el flujo se atasca.
Una de las soluciones más eficaces a estos problemas es el uso de webhooks, que permiten activar la automatización cuando se produce una acción concreta. El sistema entonces genera una URL única que se puede vincular a la acción de un usuario, por ejemplo, activando el flujo solo cuando sea necesario. Otra opción más avanzada es utilizar una llamada API para ejecutar acciones que no están incluidas en las integraciones predefinidas.
En resumen, antes de elegir el trigger, asegúrate de tener claro cuál es tu objetivo y qué eventos son críticos para tu sistema. Prueba distintas opciones y no te fíes solo de la teoría. Implementa el trigger y pruébalo en distintos escenarios para asegurarte de que se comporta como esperas.
3. Aprende a leer el log para hacer troubleshooting
Un flujo automático puede incluir múltiples componentes, cada uno con su propio conjunto de variables. Cuando algo falla, los errores tienden a acumularse, haciendo que la resolución de problemas sea cada vez más compleja. Para reducir este riesgo, nosotros solemos crear puntos de comprobación intermedios que permitan verificar si los datos obtenidos hasta ese momento y el formato son correctos. Una forma sencilla de hacerlo es enviar los datos a un documento de prueba, como un Google Doc o una hoja de cálculo de Google Sheets, donde podrás ver toda la información de forma clara y organizada.
![]()
Cada vez que se ejecuta un flujo automático, se genera un log de actividad que registra todos los eventos ocurridos en cada paso. El problema es que este registro suele contener una gran cantidad de información, de la cual solo un pequeño porcentaje suele ser realmente útil para nosotros. Por eso, es importante aprender a inspeccionar el registro y saber dónde encontrar los datos relevantes para el seguimiento de los errores.
En Make, los logs se presentan en forma de árbol de acciones, donde cada paso puede expandirse haciendo clic en el símbolo (+). Las ramas contraídas contienen los detalles necesarios para entender qué ha sucedido en cada parte del flujo. Tomarse el tiempo para familiarizarse con esta interfaz es clave para encontrar rápidamente la información necesaria para resolver los errores. Con la práctica, la interpretación de logs se vuelve más sencilla y asequible, reduciendo el tiempo necesario para detectar y corregir fallos.
Bonus: Control de errores y manejo de excepciones
Cuando desarrollamos un flujo de automatización, solemos enfocarnos en que todo funcione correctamente «en condiciones ideales». Sin embargo, la realidad es que los errores ocurren, aunque no dependan de cómo está diseñado el flujo. Servicios caídos, formatos de datos incorrectos o fallos en la conexión API son solo algunas de las causas más frecuentes.

Para evitar que se detenga todo el flujo o se generen resultados inesperados, te recomendamos incluir un sistema de control de errores y manejo de excepciones. De esta forma, el flujo no se interrumpe por un fallo puntual y se pueden aplicar estrategias para «recuperarse» del error.
Algunas plataformas, como Make, ofrecen distintas acciones predeterminadas para tratar los errores. Si el tipo de error es leve y no afecta en negativamente al proceso en su conjunto, se puede ignorar y aplazar la resolución del problema.
En cambio, si ignorar el fallo afectaría al desarrollo del proceso, se puede optar por reintentar la ejecución del paso, configurando el número y el intervalo de repetición de los intentos. Es oportuno usar esta función cuando se espera que el error sea temporal (por ejemplo, una API que no responde de forma puntual).
En tercer lugar, se pueden definir condiciones de excepción específicas para «atrapar» ciertos errores y ejecutar pasos alternativos. En otras palabras, si error no se puede solucionar con reintentos, es necesario hacer un desvío, como guardar los datos en un archivo temporal para que no se pierdan y enviar una notificación en Slack para alertar de que el flujo requiere la atención de un humano.
Con estas estrategias, el flujo se vuelve mucho más robusto, ya que no se interrumpe por errores menores, y si algo no se puede resolver automáticamente, se notifica de forma inmediata.
Conclusión
Ya sea para automatizar las acciones de marketing, crear flujos de gestión de proyectos optimizados, u organizar documentos con la IA, la sofisticación de las plataformas de automatización no para de crecer y es fácil perderse navegando entre procesos que pronto se vuelven complejos.
Con esta guía, ya tienes las 3 reglas fundamentales para encontrar la solución a tus necesidades. Recuerda: empieza por el final, elige bien el trigger y aprende a interpretar los logs para detectar errores a tiempo. Si además incorporas un sistema de control de errores y excepciones, tus flujos serán mucho más fiables y eficientes.
Si todo esto te parece interesante pero un poco abrumador, no te preocupes, no tienes que hacerlo solo. Podemos ayudarte a diseñar, optimizar y gestionar tus automatizaciones para que saques el máximo provecho de estas herramientas. Contáctanos y descubre cómo simplificar tu día a día con flujos inteligentes.
Sergio Alasia
Gestor de proyectos, automatizador, mentor, admirador del ingenio. Dirige el equipo de colaboradores de Ideomatica y enseña los trucos del oficio a quienes los necesitan. Apasionado por la exploración espacial, la ciencia y los ladrillos LEGO. Toca la guitarra, pero no en la oficina.